Web browser has the best way to manipulate the html document and the good news is we can query html document just like the browser do in golang.
Manipulate Document Element in Browser
First let's learn how we can manipulate document element in browser. When we talk about manipulating html document we talk about selecting the document, update, create and delete, and by default that is what javascript for at the first time.
Let's take a look about what javascript offer to work with document html.
querySelector: Select the first element with the given query.getElementById: Select element by the id.getElementsByClassName: Select element by class name.getElementsByTagName: Select element by tag name.element.innerText: Get string value of selected element.element.innerHtml: Get html of selected element.createElement: Create new element with the given tag name.element.append: Add new child element to the selected element.
And there is much more see MDN documentation here: https://developer.mozilla.org/en-US/docs/Web/API/Document.
Let's write simple code to select document and get text value of that element.
const athing = document.querySelector(".athing");
undefined;
athing.innerText;
("1.\t\n\tThe fun factor of the video game Uplink (vertette.github.io)");Here's the example result from hackwenews website.

Why query html in golang?
Well, manipulating html dom is very useful for frontend language which is javascript. But when you work with golang there's a chance that you might need to work with html document.
Manipulating html document with javascript API will give you good experience since you can use browser to run javascript code to query html document and then turn it to golang.
Today we will learn how to do just that. Let's start with building a scraper for hackernews.
Let's start by defining struct to hold the data to extract from hackernew site.
type Item struct {
Title string `json:"title"`
Link string `json:"link"`
Source string `json:"source"`
Author string `json:"author"`
Date string `json:"date"`
Comments string `json:"comments"`
}And here's the example in json format:
[
{
"title": "The fun factor of the video game Uplink",
"link": "https://vertette.github.io/post/funfactoruplink",
"source": "vertette.github.io",
"author": "syx",
"date": "2023-10-28T07:16:32",
"comments": 7
},
{
"title": "WinterJS",
"link": "https://wasmer.io/posts/announcing-winterjs-service-workers",
"source": "wasmer.io",
"author": "kevinak",
"date": "2023-10-28T07:19:16",
"comments": 10
}
]To do this we need two package.
golang.org/x/net/html: Official package to parse string to html document tree.github.com/go-shiori/dom: Port of javascript API to work with html document element.
Let's write function to parse string into html document tree.
func parseHTMLSource(htmlSource string) (*html.Node, error) {
doc, err := html.Parse(strings.NewReader(htmlSource))
if err != nil {
return nil, err
}
return doc, nil
}Query HTML Document
From inspector we can see that the list front page link hackernews is wrapped in .athing class.
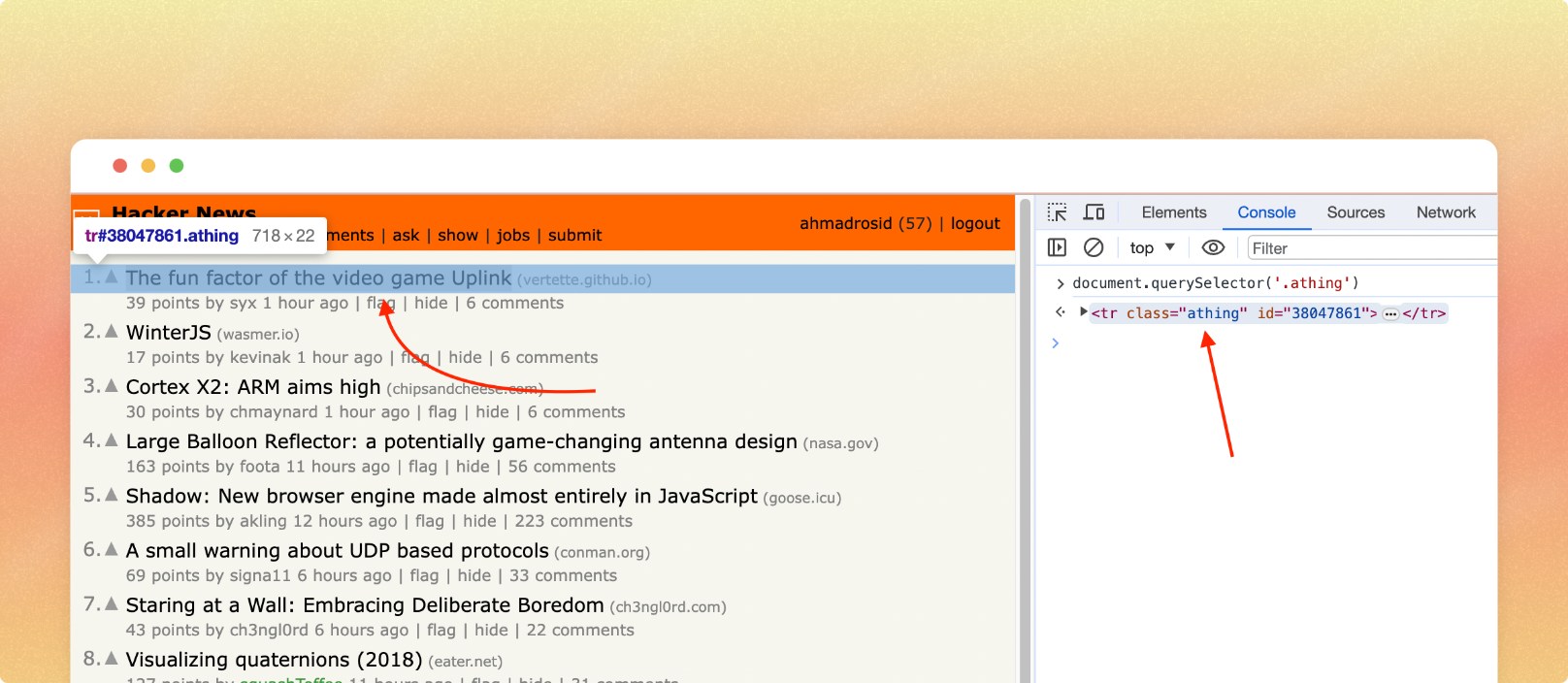
So now we can get all the element with .athing class like this:
for _, item := range dom.QuerySelectorAll(doc, ".athing") {
fmt.Println(item.InnerHtml)
}Do inspection again and here's how we can extract title text and link.
// Parse title and link
titleNode := dom.QuerySelector(item, ".titleline")
titleEl := dom.QuerySelector(titleNode, "a")
var dataItem = Item {
Title: dom.InnerText(titleEl),
Link: dom.GetAttribute(titleEl, "href"),
}
// parse source link
sitestrEl := dom.QuerySelector(titleNode, ".sitestr")
if sitestrEl != nil {
dataItem.Source = dom.InnerText(sitestrEl)
}The next data we need to extract is points, date, and total_comments but this element is not inside .athing element. To solve this issue we can find next element after .athing like this:
// parse username to string
hnuserDom := dom.QuerySelector(subtextDom, ".hnuser")
if hnuserDom != nil {
dataItem.Author = dom.InnerText(hnuserDom)
}
// parse date post
ageDom := dom.QuerySelector(subtextDom, ".age")
if ageDom != nil {
dataItem.Date = dom.GetAttribute(ageDom, "title")
}For comments we only care to get the number, but there are other element which is action to hide and add flag to the link and the element is giving us text like 6 comments.
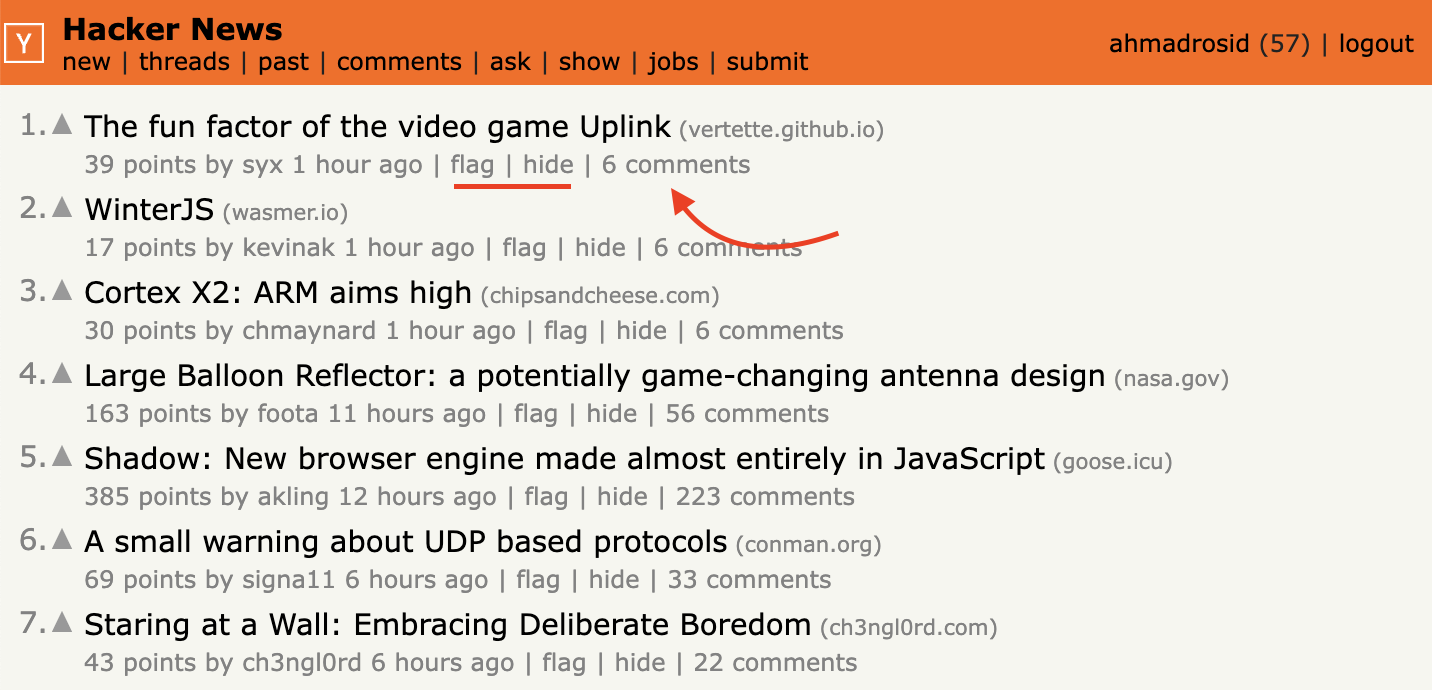
So we can get the last element and then remove string comments only take 6 string and turn into integer.
// parse comments to number
subtextDomChildren := dom.QuerySelectorAll(subtextDom, "a")
if len(subtextDomChildren) > 0 {
lastEl := subtextDomChildren[len(subtextDomChildren)-1]
if comments, err := strconv.Atoi(
strings.TrimSuffix(dom.InnerText(lastEl),
" comments",
)); err == nil {
dataItem.Comments = comments
}
}
result = append(result, dataItem)And here's the complete code to parse the html dom.
func parseContent(content string) []Item {
var result = make([]Item, 0)
doc, err := parseHTMLSource(content)
if err != nil {
println("Parse error")
return result
}
if doc == nil {
println("Doc is nil")
return result
}
for _, item := range dom.QuerySelectorAll(doc, ".athing") {
// Parse title and link
titleNode := dom.QuerySelector(item, ".titleline")
titleEl := dom.QuerySelector(titleNode, "a")
var dataItem = Item {
Title: dom.InnerText(titleEl),
Link: dom.GetAttribute(titleEl, "href"),
}
// parse source link
sitestrEl := dom.QuerySelector(titleNode, ".sitestr")
if sitestrEl != nil {
dataItem.Source = dom.InnerText(sitestrEl)
}
next := dom.NextElementSibling(item)
subtextDom := dom.QuerySelector(next, ".subtext")
// Parse score value to int
scoreDom := dom.QuerySelector(subtextDom, ".score")
if scoreDom != nil {
pointLabel := " points"
scoreText := dom.InnerText(scoreDom)
points, _ := strconv.Atoi(scoreText[:len(scoreText)-len(pointLabel)])
dataItem.Points = points
}
// parse author name to string
hnuserDom := dom.QuerySelector(subtextDom, ".hnuser")
if hnuserDom != nil {
dataItem.Author = dom.InnerText(hnuserDom)
}
// parse user name to string
ageDom := dom.QuerySelector(subtextDom, ".age")
if ageDom != nil {
dataItem.Date = dom.GetAttribute(ageDom, "title")
}
// parse comments to int
subtextDomChildren := dom.QuerySelectorAll(subtextDom, "a")
if len(subtextDomChildren) > 0 {
lastEl := subtextDomChildren[len(subtextDomChildren)-1]
if comments, err := strconv.Atoi(
strings.TrimSuffix(dom.InnerText(lastEl),
" comments",
)); err == nil {
dataItem.Comments = comments
}
}
result = append(result, dataItem)
}
return result
}Conclusion
I found this way of working with html document to extract data from it become more fun. There are a lot of other library that offer other way to query html element but stay close with browser api is better because we can inspect the document with browser and write the query in golang.
This technique I use to my product Readclip - Feed deck plase check it out the product it's will help you organize your bookmark links with more feature for discover interesting article from internet.