OpenAI has released a new model for speech recognition, which is available for free and open source on GitHub. One of the uses for it was to convert YouTube videos to text.
In this article, we will discuss how to use OpenAI Whisper to transcribe YouTube videos to text using Python and FastAPI.
Install Packages
First, let's install the packages we need. We can store all the pip packages we need in requirements.txt files.
whisper
git+https://github.com/openai/whisper.git
pytube
fastapi
uvicornOne thing to keep in mind about the pip package: there is already a package named whisper, so we need to tell pip that we want the whisper package from OpenAI that is currently available on GitHub.
Virtualenv (Optional)
You can also use the virtualenv to create isolated package for this so that we can makesure we are installing the correct package. You can do this by running the following command:
pip install virtualenvOnce virtualenv is installed, you can create a new virtual environment using the virtualenv command.
virutlenv youtextThis will create a new directory called youtext in your current working directory, containing a copy of the Python executable and the pip package manager.
To start using the virtual environment, you need to activate it. On Unix-like systems (such as Linux or macOS), you can do this by running the following command:
source youtext/bin/activateAnd now you can install all the necessary package with this command.
pip install -r requirements.txtDownload YouTube Video
The first thing we need to do is to download YouTube videos. We already have the package to do that, which is pytube, so here is how we can download it. First, create a download.py file.
import hashlib
from pytube import YouTube
def download_video(url):
yt = YouTube(url)
hash_file = hashlib.md5()
hash_file.update(yt.title.encode())
file_name = f'{hash_file.hexdigest()}.mp4'
yt.streams.first().download("", file_name)
return {
"file_name": file_name,
"title": yt.title
}Here, we are using MD5 to hash the file name when saving the video that has already been downloaded. You can use the video title as the file name, but sometimes it is a bit tricky to access it. Therefore, for this article, we will go with the MD5 file name.
Transcribe to Video
We already have the video file, and now we can transcribe it using the Whisper package. Now, create a file called transcribe.py; you can name the file whatever you want, but for now, we'll go with this name.
To transcribe to video to text using whisper we can simply just load the model and transribe it like this.
model.transcribe(video["file_name"])In this case, we are using base.en models. There are several models available; choose the model that best suits your needs. See the documentation here.
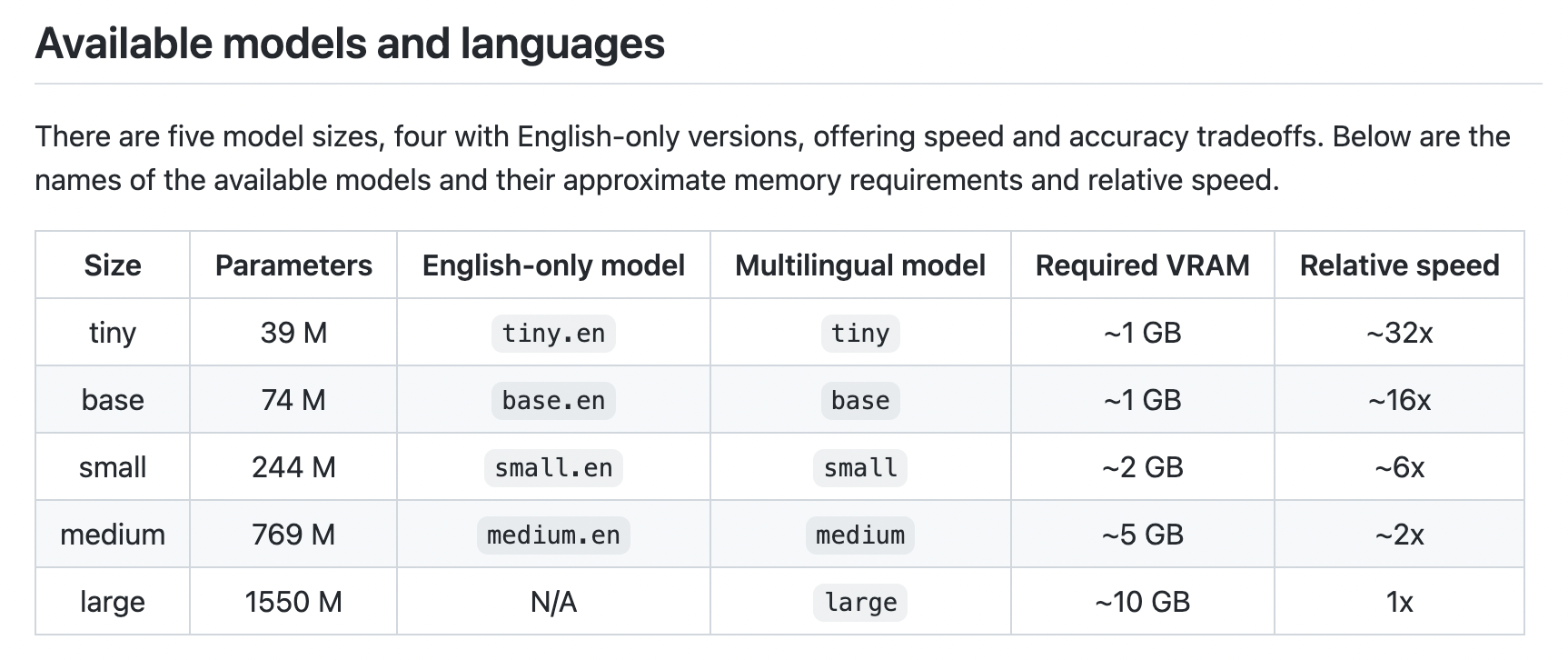
Now we can just import the download module that we alread created before and use it to download video and then transcribe it with the whisper package.
import whisper
import os
from download import download_video
model_name = "base.en"
model = whisper.load_model(model_name)
def transcribe(url):
video = download_video(url)
result = model.transcribe(video["file_name"])
os.remove(video["file_name"])
segments = []
for item in result["segments"]:
segments.append(format_item(item))
return {
"title": video["title"],
"segments": segments
}There are several fields available from transcribing the video using Whisper, but in this case, we only care about the start and text fields. We will use this data to display the text and link it to the YouTube later. So we can get the exact words when we open the video on YouTube.
So, here is how we can format the results from the whisper.
def format_item(item):
return {
"time": item["start"],
"text": item["text"]
}Serve to the Internet
Now we already have the core features for our YouTube video transcription, let's make an API so that we can deploy it as a web app so that you can monetize it and maybe build a billion-dollar startup from it.
To make that happen, we are going to use FastAPI to build the web server and create a client interface using HTML and JQuery to interact with the API we are going to make.
from fastapi import FastAPI, Form
from fastapi.responses import HTMLResponse
from transcribe import transcribe
app = FastAPI()
@app.get("/")
def index():
index = ""
with open("static/index.html", "r") as f:
index = f.read()
return HTMLResponse(index)
@app.post("/api")
def api(url: str = Form()):
data = transcribe(url)
return {
"url": url,
"data": data
}We are defines two routes here:
/: This route is a GET endpoint that returns an HTML response containing the contents of a file called static/index.html./api: This route is a POST endpoint that takes a url parameter from the request body, and returns a JSON object containing the url and the result of calling the transcribe function with the url as an argument.
The index and api functions are decorated with FastAPI route decorators, which specify the HTTP method and route for the endpoint.
We also serve the static file to give the user interface when index route / are visited.
@app.get("/")
def index():
index = ""
with open("static/index.html", "r") as f:
index = f.read()
return HTMLResponse(index)HTML User Interface
We will using CDN TailwindCSS for styling our UI and JQuery to interacting with API that we already created.
<script src="https://cdn.tailwindcss.com"></script>
<script
src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.3/jquery.min.js"
integrity="sha512-STof4xm1wgkfm7heWqFJVn58Hm3EtS31XFaagaa8VMReCXAkQnJZ+jEy8PCC/iT18dFy95WcExNHFTqLyp72eQ=="
crossorigin="anonymous"
referrerpolicy="no-referrer"
></script>For the UI, we will provide just the header form input and a display container for transcribed text like this.
<body>
<div class="text-5xl font-extrabold max-w-3xl mx-auto p-12 text-center">
<span
class="bg-clip-text text-transparent bg-gradient-to-r from-pink-500 to-violet-500"
>
YouText
</span>
<p class="text-2xl font-light text-gray-600">
Convert YouTube video to Text.
</p>
</div>
<form id="form" class="max-w-3xl mx-auto space-y-4 p-8">
<input
name="url"
class="rounded-sm p-2 w-full border"
placeholder="Type youtube url here..."
/>
<button
type="submit"
class="text-white bg-violet-500 rounded-sm w-full py-2"
>
Submit
</button>
</form>
<div class="max-w-3xl mx-auto space-y-4 p-8 bg-gray-200 relative">
<h2 id="title" class="font-semibold text-2xl"></h2>
<div class="absolute top-2 right-2 hover:cursor-pointer" id="copy-text">
<!-- SVG Icon, get it here: https://gist.github.com/ahmadrosid/73b006f9265a262ace151bbce3a2d7fb -->
</div>
<div id="result"></div>
</div>
</body>And calling the API and formatting the output for our page is done with JQuery like this.
<script>
$(document).ready(() => {
$("#form").submit(function (e) {
e.preventDefault();
let formData = $(this).serialize();
let req = $.post("/api", formData, (data) => {
let strTemp = "";
data.data.segments.forEach((item) => {
strTemp += `<a class="hover:text-violet-600" href="${
data.url
}&t=${parseInt(item.time, 10).toFixed(0)}s">${item.text}</a>`;
if (item.text.includes(".")) {
$("#result").append(`<p class="pb-2">${strTemp}</p>`);
strTemp = "";
}
});
if (strTemp !== "") {
$("#result").append(`<p>${strTemp}</p>`);
}
$("#title").append(data.data.title);
$("#copy-text").on("click", function () {
let $input = $("<textarea>");
$("body").append($input);
let texts = data.data.segments
.map((item) => item.text)
.join("")
.trim();
$input.val(texts).select();
document.execCommand("copy");
$input.remove();
});
});
req.fail((err) => {
console.log(err);
});
});
});
</script>Here is the look of our user interfaces.

Conclusion
OpenAI has released a new model for speech recognition, which is available for free and open source on GitHub. One of the uses for it was to convert YouTube videos to text.
In this article, we discussed how to use OpenAI Whisper to transcribe YouTube videos to text using Python and FastAPI. We installed the necessary packages, downloaded the YouTube video, transcribed it to text using Whisper, and served it to the internet using FastAPI.
We also created an HTML user interface with TailwindCSS and JQuery to interact with the API. Finally, we tested the application and it worked as expected. Get the full source code here.
Thank you for reading this article! I hope you found it helpful. If you have any questions or comments, please feel free to reach out to me.